
我们的 mission 之一是熵减, 在目前这个 stage 我们能做的是
- Context builder (最好的呈现有用的信息)
- Filter (最大程度的过滤掉无用的信息)
这里我们讨论一下我们对于 Filter 的一些想法. Filter 的主要可以过滤一下几类
- 不良信息
- 内容农场
- 低质内容
并且让这个 Filter 可以做到
- 黑白名单提供过滤的灵活性
- Public list - 开放给社区参与维护 (或者整合其他的开源项目)
- Private list - 允许每个用户自己录入和维护属于自己的filter (手动录入, 文件上传, github url等)
上述是一些简单的思考, 具体的设计会基于这些思考. 欢迎F友参与讨论和提出意见!
下面是一些 reference
广告
https://adblockplus.org/subscriptions
内容农场
https://github.com/danny0838/content-farm-terminator
综合
http://github.com/bcaso/Google-Chinese-Results-Whitelist
http://github.com/bcaso/Google-Chinese-Results-Whitelist
如果你有其他觉得能帮到F搜更好的搭建这个filter的资源, 请回复此帖!
关联
 以上理解是否正确?
以上理解是否正确?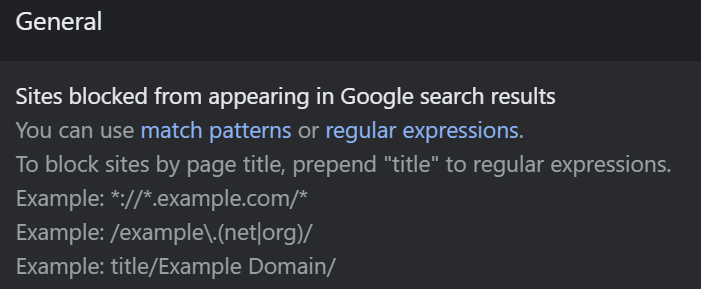

 顺手加上油猴还有ublock,又一个谷歌浏览器……
顺手加上油猴还有ublock,又一个谷歌浏览器……