
我们的 mission 之一是熵减, 在目前这个 stage 我们能做的是
- Context builder (最好的呈现有用的信息)
- Filter (最大程度的过滤掉无用的信息)
以下是 F搜团队对于 Context builder 的一些思考, 有兴趣的F友可以参与下讨论!
用户想要什么
当用户完成搜索以后, 一个高效检索的注意力区域应该是这个 “Golden Triangle”.

那我们需要有一个高效的 context builder (上下文建立器) 帮助用户更快速的找到自己想要的, 用户的需求可以简化为下面两类问题
- 用户知道自己想要找什么 (有目的检索与匹配信息)
- 用户不知道自己想要什么 (有方向获取与拓宽信息)
抽象一下变成
- 知识/信息检索 (Indexing knowledge)
- 知识/信息探索 (Exploring knowledge)
问题拆解
因此 context builder (上下文建立器) 需要专注在人体的感官摄入来最高效的完成上述两件事情. 在这个方面, 让我们专注视觉和听觉 (暂时忽略触觉, 味觉和嗅觉, we’re not metaverse ready yet LOL)
听觉 + 视觉 = 视频
视频适用于什么呢?
- 无目的的信息获取 (娱乐)
- 复杂的信息获取 (教程)
 不是我们专注的方向, 所以可以忽略这个部分 (不是排除视频结果, 而是排除直接播放视频)
不是我们专注的方向, 所以可以忽略这个部分 (不是排除视频结果, 而是排除直接播放视频)
视觉 = 文字 + 图片
20年前搜索引擎刚刚起步的时候, 大家都在谈论 ranking, 但是如果你是一个经常搜索的用户, 你会发现 ranking 在 2010 年左右就已经非常成熟了, 后续在这方面都是 marginal improvement (与其说在改进 ranking , 不如说是在和 SEO 在斗智斗勇).
所以一个更加现代的问题是信息的组织 + Ranking, 后者是可以通过低成本的方式去 bootstrap 的, 前者是我们想发力的地方.
解决方法
在讨论解决方法前, 让我来分享一下我们观察到的一个有趣的现象.
任何平台都需要内容和用户的积累 (网络效应 & 鸡与蛋的问题). 在这个问题上, 我们认为鸡是无法永久保存的 (有寿命的), 但是蛋可以 (无寿命的). 所以一个比较好的做法是找一个累积了很多蛋的领域 (冷启动), 让鸡可以高效高质的产蛋 (差异化).
 以下是累积了很多蛋的领域的例子
以下是累积了很多蛋的领域的例子
3500年的文字积累 (first appearance circa 3500 BC) → Google
180年的图片积累 (first appearance circa 1826) → Facebook & Instagram
130年的视频积累 (first appearance circa 1889 AD) → YouTube
以下是累积了很多蛋的领域 + 让鸡可以高效高质的产蛋的例子
16年的长视频积累 (YouTube and etc.) → TikTok
22年的长文积累 (Blogger and etc.) → Twitter
不难看到, 所有上述的蛋都是视觉和听觉 (所以现在Meta Facebook 要突破), 但所有这些都会汇总到搜索引擎这边进行检索. 这样看来, 现在的搜索不是单单是准确排名的问题 (Ranking), 而是在如此多的信息输入中能否高效建立认知并且找到答案的问题 (↓ Entropy).
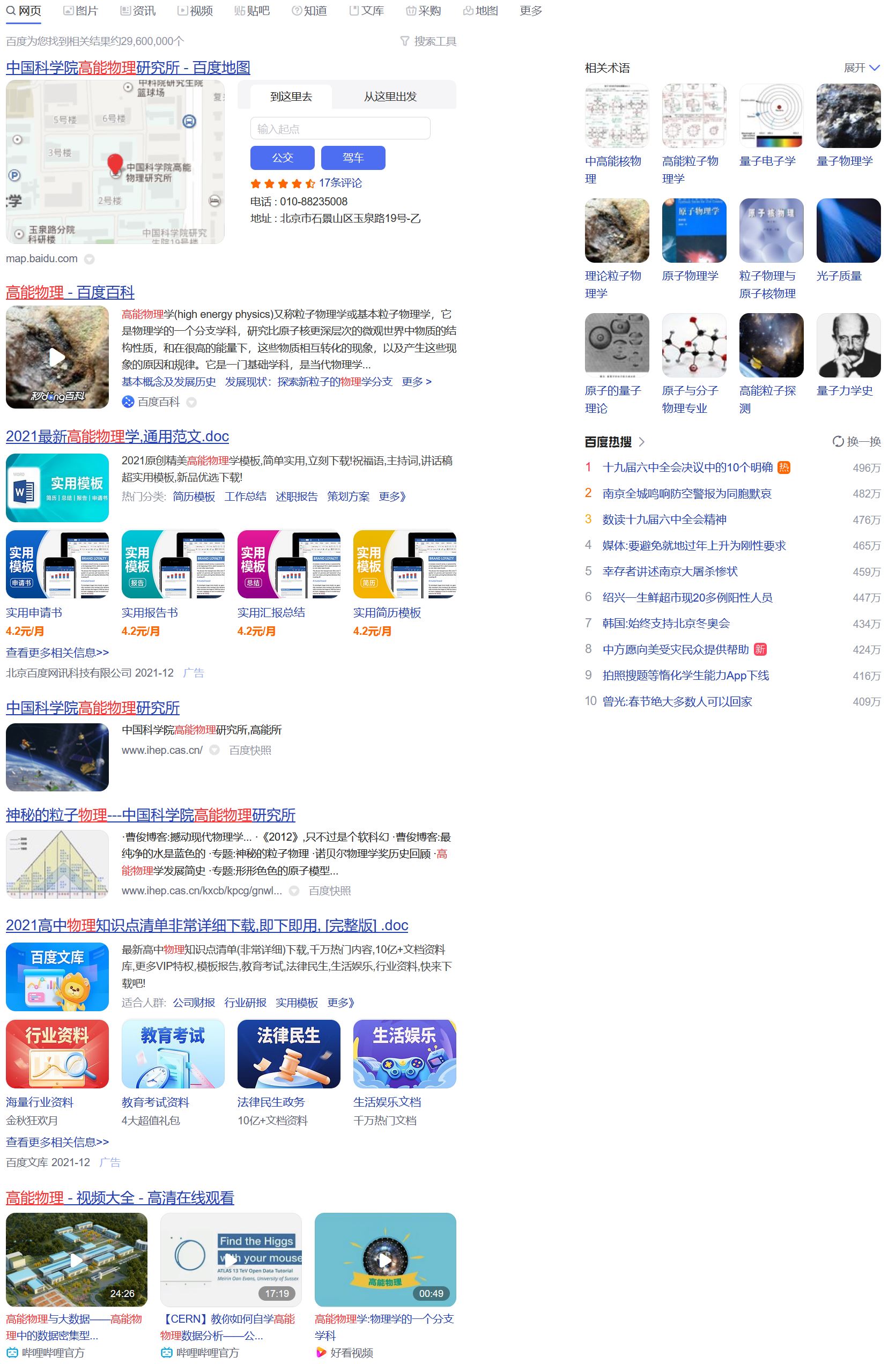
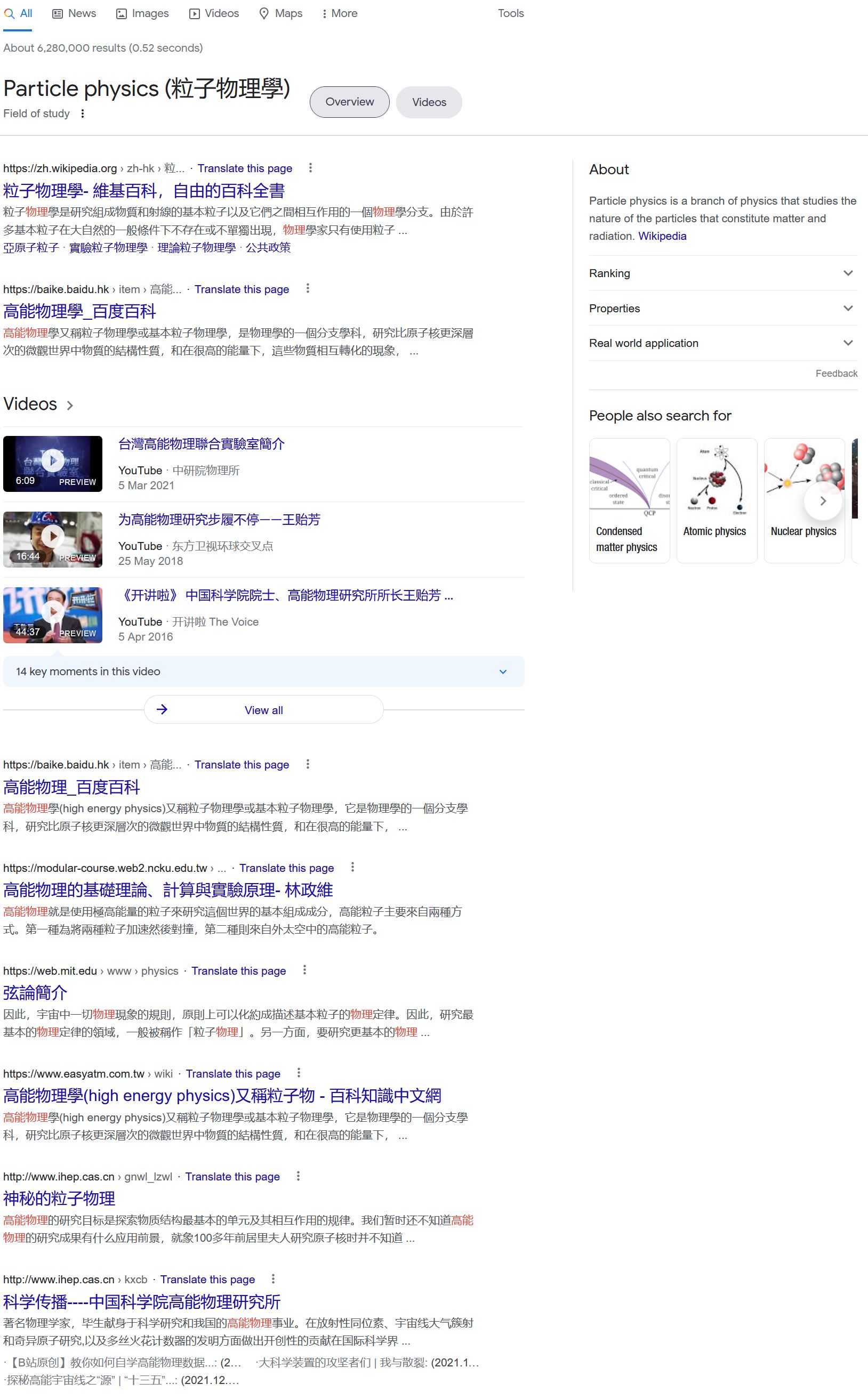
比如说我搜索一个我不熟悉的领域 - “高能物理”
解决方案 1
解决方案 2
实现方式 - Context Builder
Maybe 我们能做些什么? 回到最初我们提到的 “Golden Triangle” - 那一个好的实现方式就是在那个区域内, 通过文本和图片帮助用户快速建立认知和选择最相关的信息. 我们想做一个 Context Builder 帮助用户
建立上下文 → 判断信息相关度 → 消费信息
抽象的说 - “Answers instead of lists”. 这里所说的 “Answers” 不是Quora和知乎那种的问答, 而是第一页的搜索结果自身是个 answer.
那这个 Context Builder 正是这个如何通过文本 + 图片(包括视频缩略图) 去完成上述的一个"how to".