
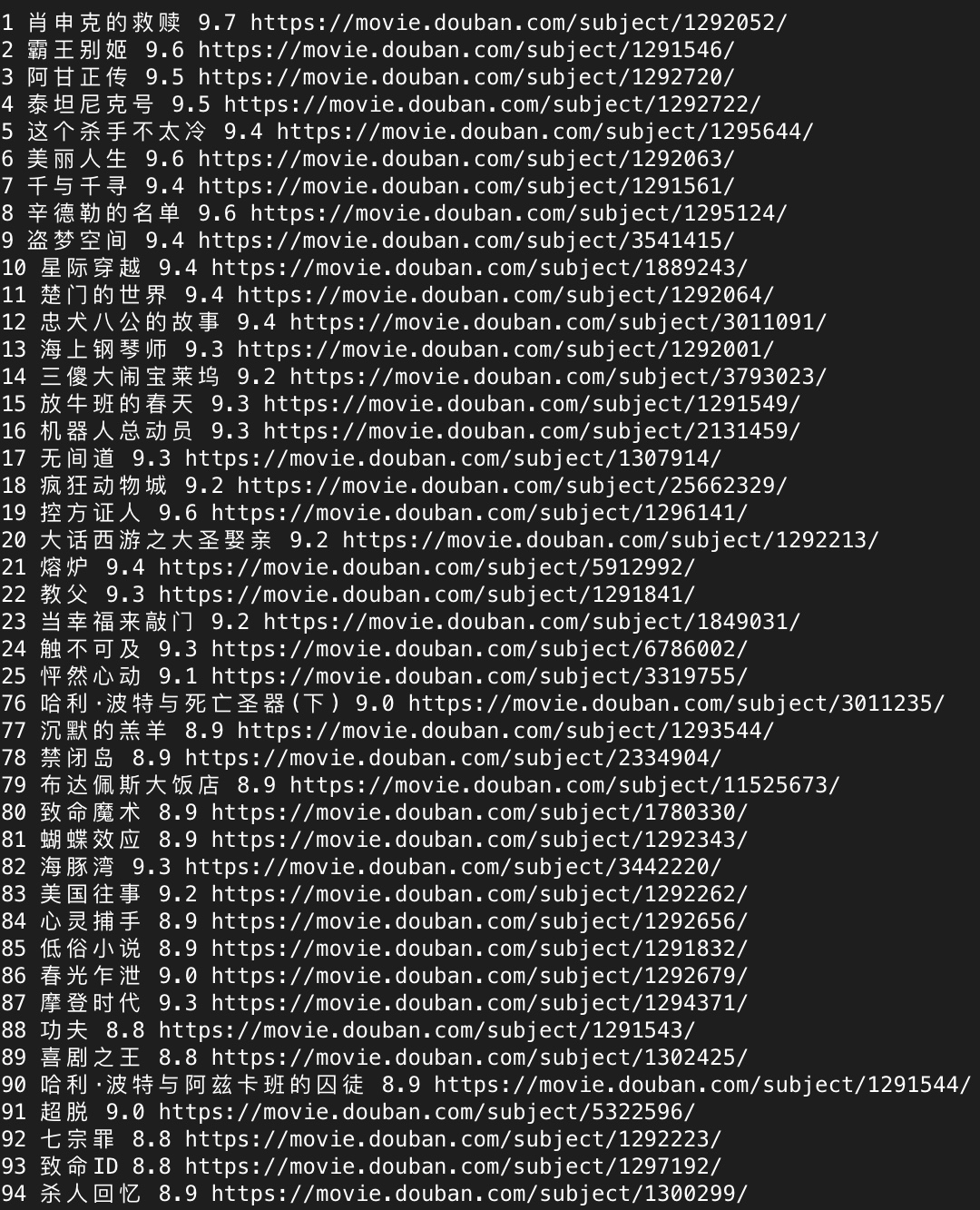
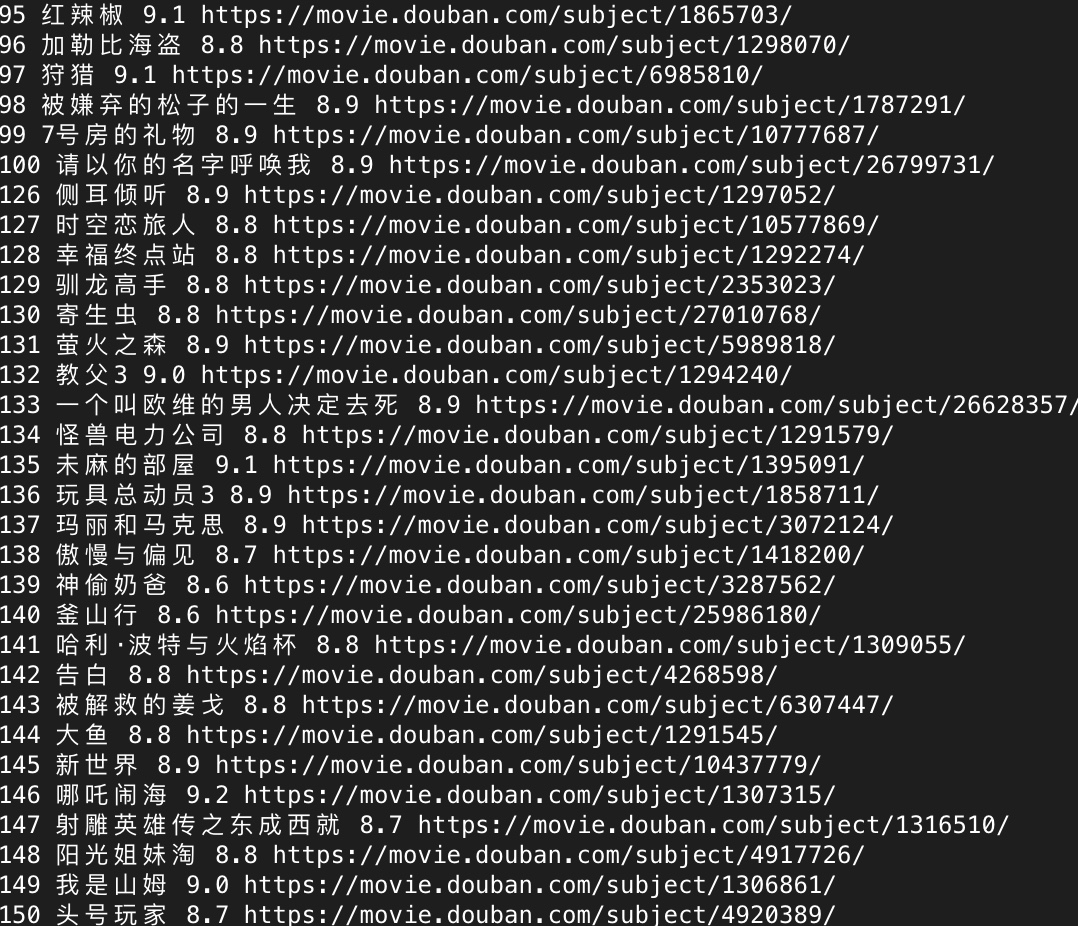
本人小白,只会这些简单的项目emmm……
代码很简单,引用了requests和pyquery库
import requests
from pyquery import PyQuery as pq
for url in ['https://movie.douban.com/top250?start={}'.format(page) for page in range(0,250,25)]:
html = pq(requests.get(url, headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.80 Safari/537.36'}).text)
for item in html('.item').items():
num = item.find('.pic em').text()
title = item.find('.title').html()
link = item.find('.pic a').attr('href')
star = item.find('.rating_num').text()
print(num, title, star, link)
厉害,我是纯白,只会无代码的PowerBi爬一些信息 
可以的,不过这只是简单的打印,还需要存储下来。可以尝试csv或者excel保存。